关于Sudis
# 产品概述
高速分布式缓存数据库 Sudis是一个功能强大的数据存储系统,具有高性能、丰富的数据结构、持久化、分布式支持等特点。它应用于缓存、消息队列、会话存储、计数器、排行榜、实时分析等各种场景,并通过其简单的API和丰富的功能满足了开发者对高性能数据存储的需求。 它主要有以下特点和功能:
内存存储:
Sudis主要将数据存储在内存中,因此读写速度非常快。与传统关系型数据库相比,不需要从磁盘读取数据,从而大大提高了访问速度。
数据结构丰富:
Sudis支持多种数据结构,除了常见的String(字符串)、List(列表)、Set(集合)、Hash(哈希表)和Sorted Set(有序集合),还提供了以下几种特殊的数据结构。
- Bitmaps(位图):位图是一种特殊的字符串,它的每一个bit都可以进行操作。在位图中,可以设置、获取和计算位的值,适用于一些需要进行位级别操作的场景,如权限控制、在线状态跟踪等。
- HyperLogLog:HyperLogLog是用于实现基数(cardinality)估计的数据结构。它可以用来估计一个集合中元素的数量,且占用的空间很小。通过HyperLogLog可以快速估算一个集合的基数,但会存在一定的估计误差。
- Geo(地理位置):Sudis提供了一系列的地理位置相关的命令,使得可以在Sudis中存储和查询地理位置信息。可以方便地将经纬度坐标与其他信息关联起来,如存储地理位置坐标和搜索附近的位置。
- Streams(流):Streams是一种轻量级的消息流发布和消费模型。它可以实现多个生产者和消费者之间的异步通信,并支持发布者和订阅者之间的消息传递。Streams可以用于构建消息队列、日志订阅等场景。这些数据结构可以适用于不同的应用场景,Sudis提供丰富的操作方法和数据存储方式。
持久化:
Sudis支持两种持久化方式,分别是RDB和AOF(Append Only File)。RDB是将Sudis的数据在指定时间间隔内保存到硬盘上的快照方式,而AOF是通过追加方式将每条Redis命令写入日志文件。通过持久化,可以在Sudis重启时将数据恢复到内存中,保证数据的可靠性。
高效的读写操作:
除了内存存储的优势外,PowerDB还实现了高效的读写操作。例如,可以直接在String数据结构上进行原子性的递增和递减操作,对List和Set等数据结构可以进行快速的插入、删除和查找操作,实现高效的数据处理。
分布式支持:
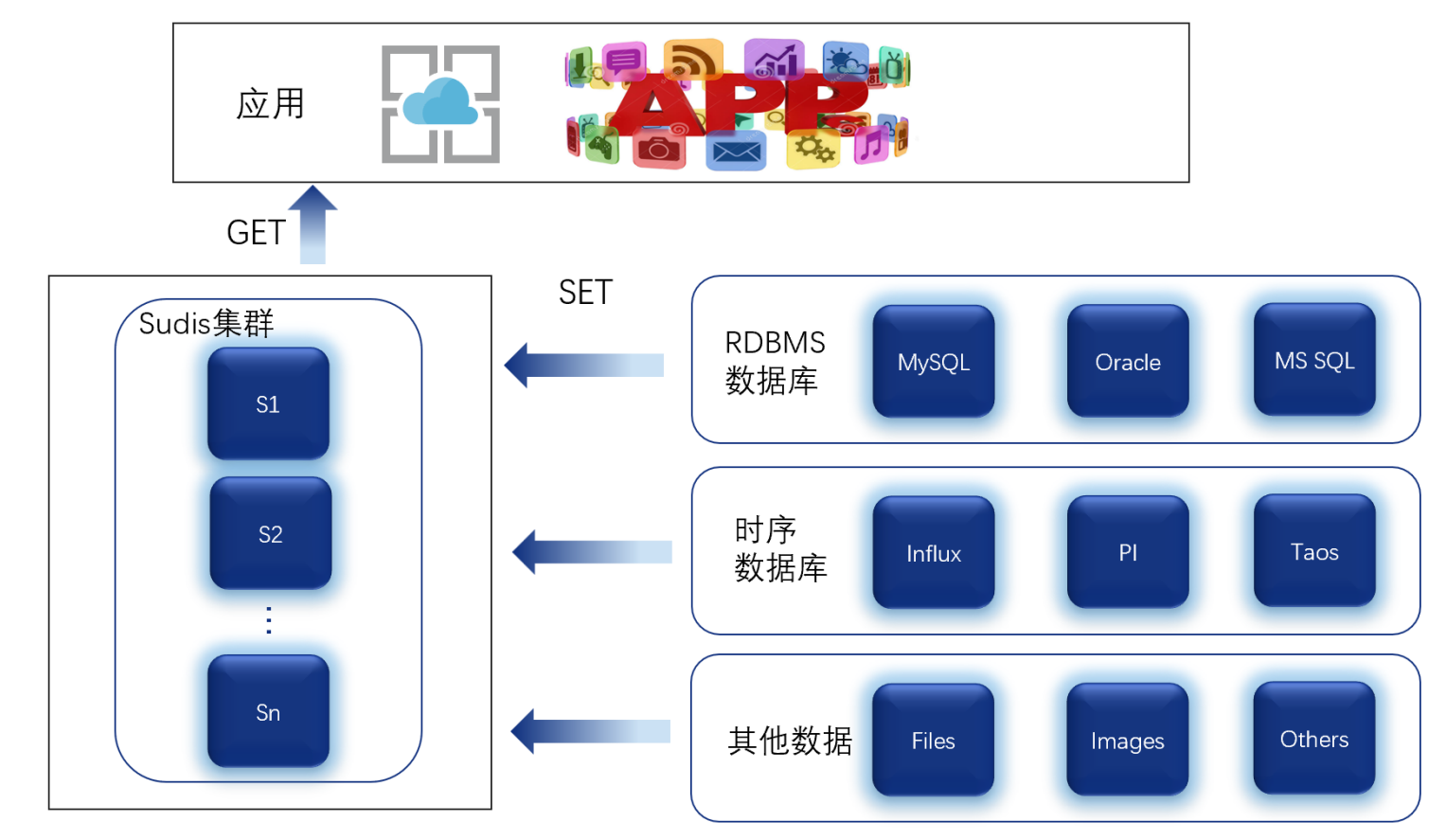
提供了Cluster分布式解决方案,可以将数据分布在多个节点上,提供更好的高可用性和负载均衡能力。Cluster使用哈希槽(hash slots)的方式将数据分片,每个节点负责处理一部分数据,实现水平扩展和分布式存储。
发布/订阅:
可以实现消息的发布和订阅机制。可以将消息发布到指定的频道,所有订阅了该频道的客户端都可以接收到该消息,实现了简单的消息队列功能。
事务支持:
通过MULTI、EXEC、WATCH和DISCARD等命令实现事务的原子性操作。可以将多个命令组合成一个事务,保证这些命令在执行过程中不被其他客户端中断。
最新版本 Sudis2.0兼容 Redis 7.0 版本协议,集群版部署理论上支持的节点数为16384,该数量为Redis设计的slot上限。Sudis旨在提供低延迟高并发的需要,可满足业务在缓存、存储、计算等不同场景中的需求,为应用提供内存级的数据访问、存取服务。
- 数据库 Sudis 产品可为游戏、电商、视频、行业应用、金融等行业客户提供稳定的服务。
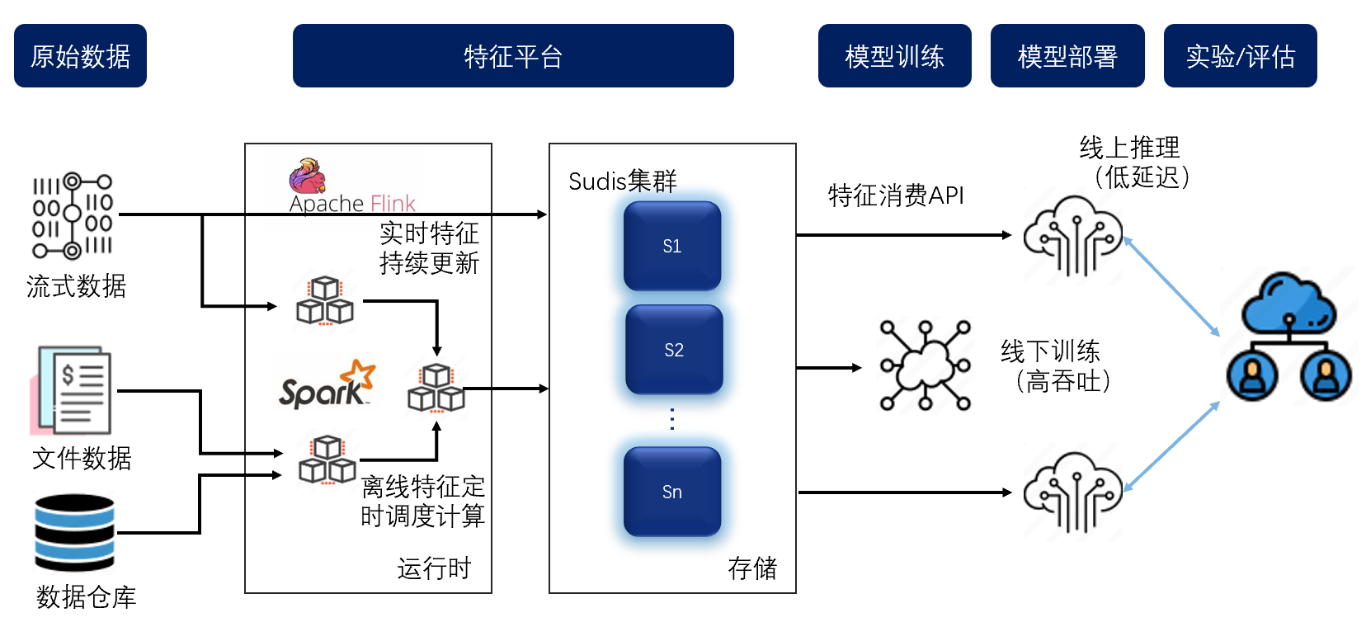
- 此外还可以为行业AI运算提供数据加速的服务,能提供高达10倍的算力效率的同时,帮助客户节省底层基础设施的投入。
# 产品优势
# 多并发、高性能
- Sudis使用多线程架构,高性能私有协议,在高压力下提供更高的吞吐量。在并发设计方面,Sudis采用双螺旋多线程设计,在网络消息收发处理和IO业务处理都使用多线程机制,极大的提高访问并发吞吐量。
- Redis仅在最新的版本6、7采用网络层多线程设计,其IO业务仍是单线程处理,单节点并发提升不显著。
# 自主可控
- 公司拥有100%自主知识产权,基于C/C++实现,所有底层核心源代码完全自研可控,不基于任何数据库开源代码,是真正意义上的、完全自主可控的国产数据库。

# 信创芯片亲和性适配
Sudis已成功适配国内主流信创芯片和信创操作系统,包括飞腾、鲲鹏、海光等主流国产CPU,以及麒麟、统信、凝思、ctyunOS等国产操作系统。通过优化Sudis与CPU的节点亲和配置,充分利用信创芯片的架构设计特点,大大提升了Sudis网络和I/O多线程的处理效率。相比Redis缓存数据库,Sudis在并发测试中展现出更佳的性能表现
鲲鹏和麒麟证书

飞腾和统信证书

# 高可用架构
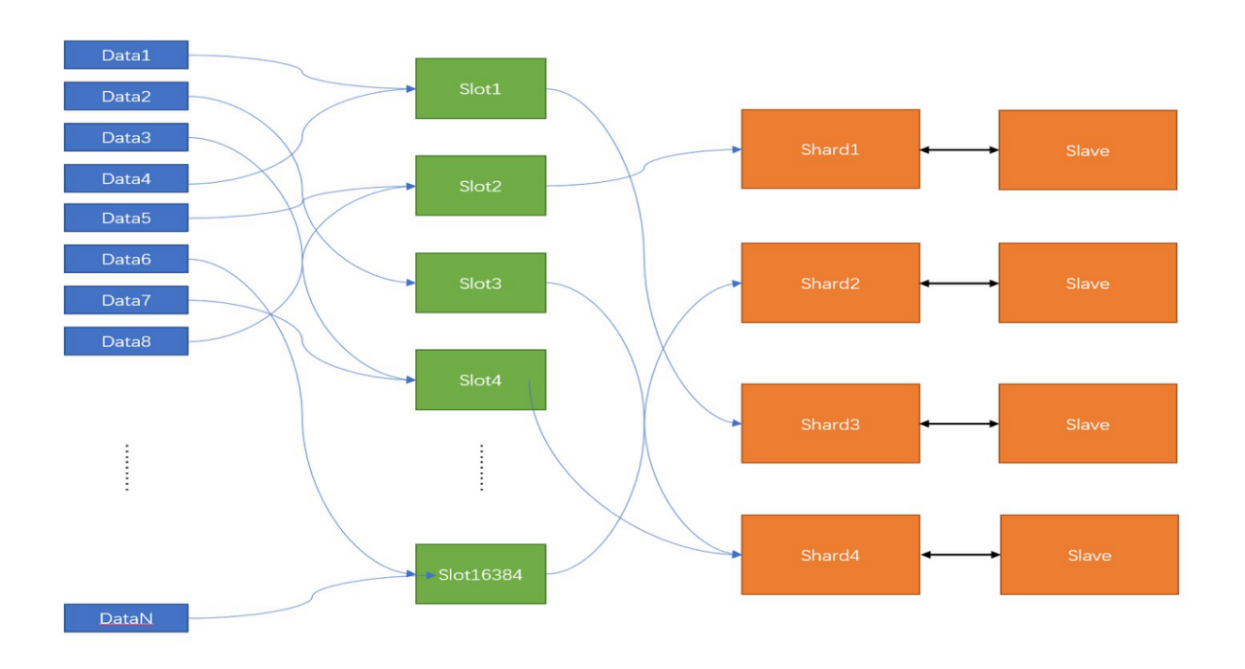
- 集群模式是一种分布式架构,通过将数据分散到多个节点上实现高可用性和扩展性。每个节点负责部分数据的读写操作,当节点宕机时,其他节点可以继续处理请求。集群模式需要至少1个主节点和1个从节点,并使用哈希槽分配算法来管理数据分布。这种架构可以扩展到多个节点,提供更高的性能和容量
- 集群架构采用Slot(哈希槽)和Shard(分片)的设计,对于客户端的请求的key,根据公式HASH_SLOT=CRC16(key) mod 16384,计算出映射到哪个分区上。Sudis 提供秒级的故障切换能力。
# 性能弹性扩展
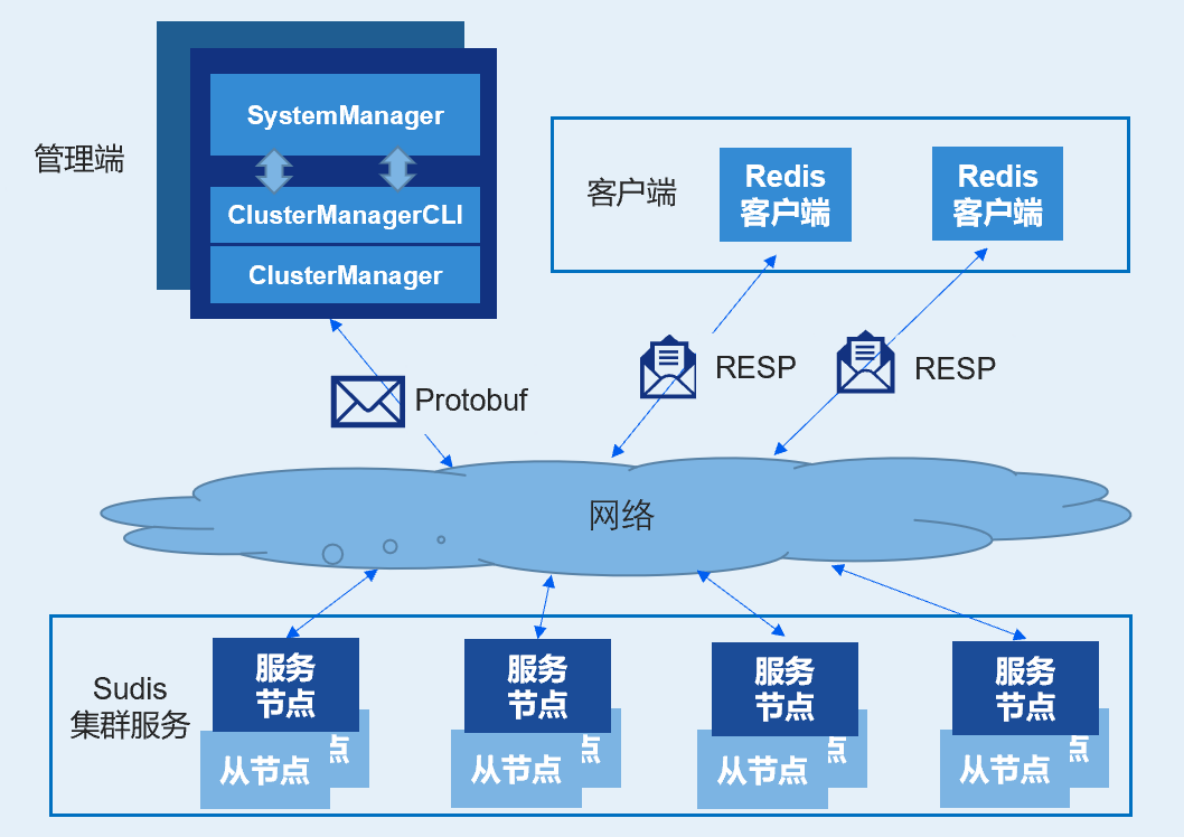
- Sudis采用分布式系统设计方法,支持群集环境的高效线性扩展能力,集群中所有的节点按照负载均衡的原则承担数据和算力服务。服务节点之间是端对端的,每个服务节点一般包括一主二从,因此不存在单点故障。
- 不同于Redis Gossip协议多对多的设计,Sudis采用一对多的Protobuf协议,集群管理消息量少,最直接的效应将网络流量降至最低。
- 此外Sudis Cluster Bus消息经过精简优化,相对于Redis Cluster Bus的消息数据量小,提升集群运行效率。
- Sudis高可用架构最大化利用网络带宽,避免在大集群部署环境下随着节点数增加网络开销呈指数增长。
- 得益于Sudis Protobuf及Cluster Bus的设计,Sudis具有高效的线性扩展能力,最高可支持16384个节点的部署。受制于Redis Gossip,redis集群往往不能超过100个节点,Sudis可以在1000个节点环境下正常运行。
# 易用的GUI管理工具
GUI管理工具,追求极致的用户体验,将复杂的运维工作完全智能化。数据备份、数据恢复完全自动;扩容、升级、IDC机房迁移轻松完成。此外我们还兼容目前主流的Redis管理工具比如QuickRedis。
下图为Sudis集群的管理功能界面示例:
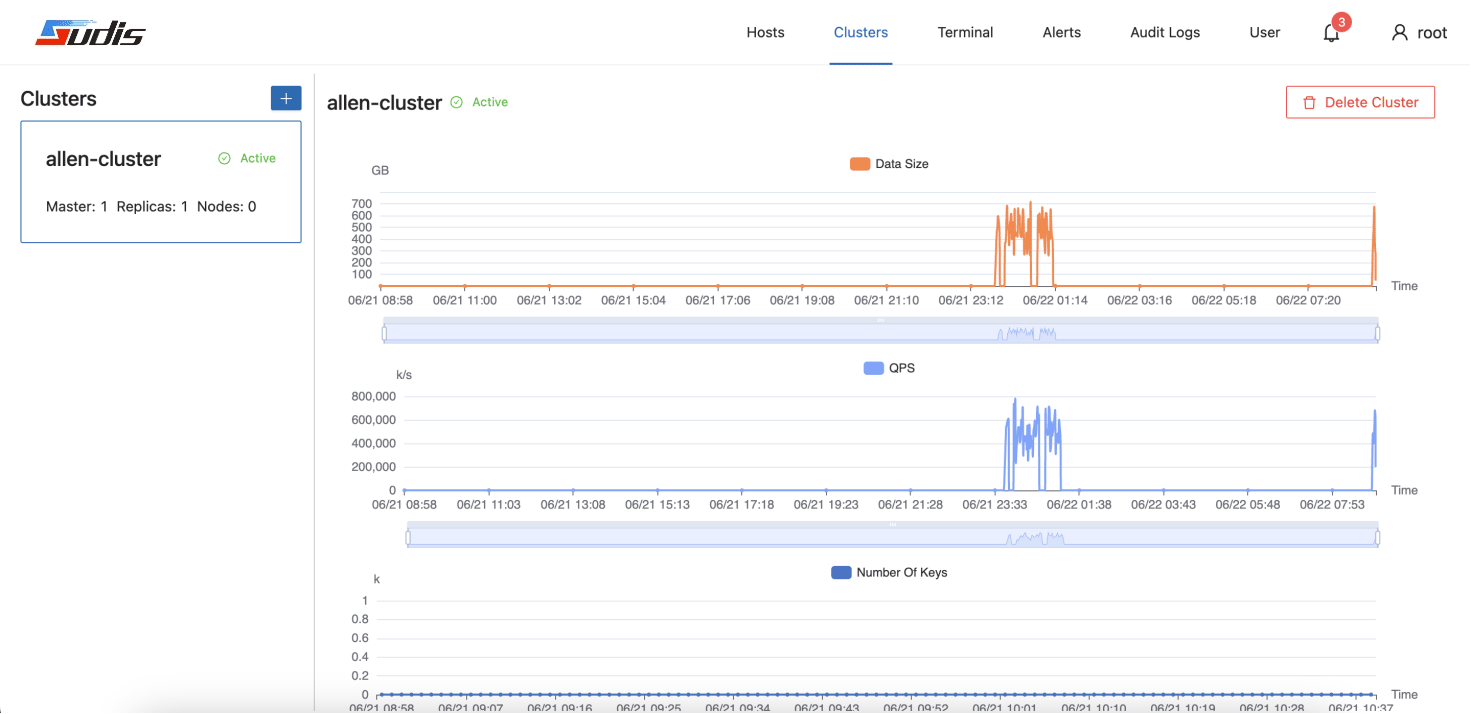
下图为Sudis主机管理界面示例:
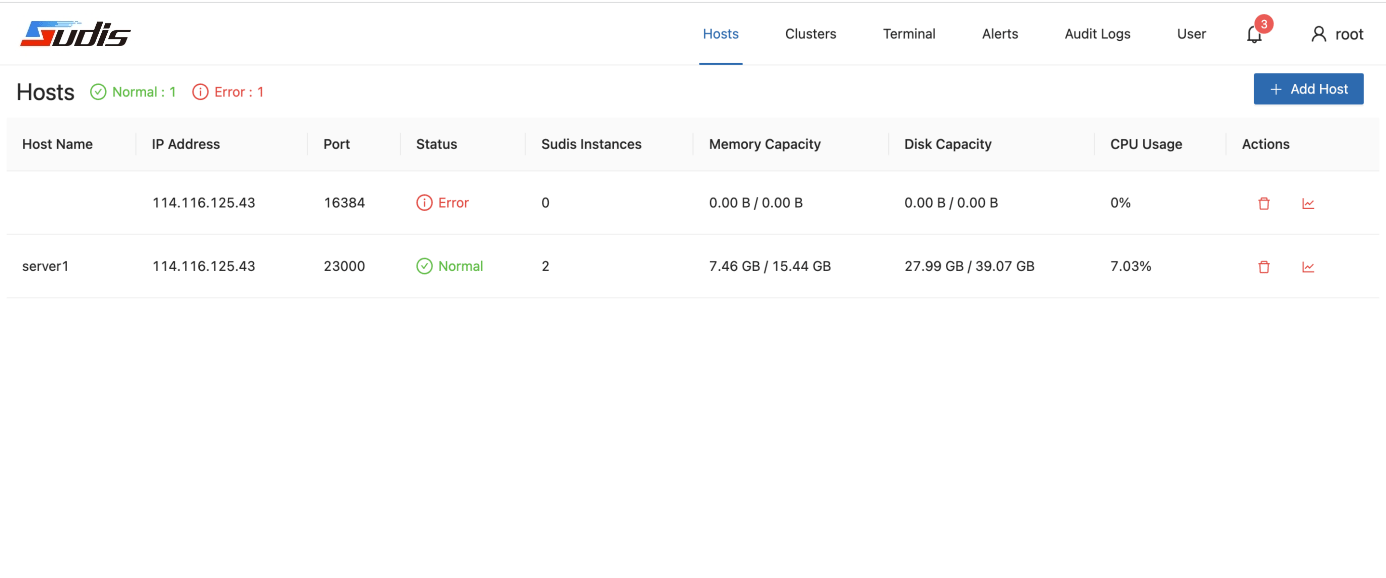
下图为Sudis用户管理界面示例:
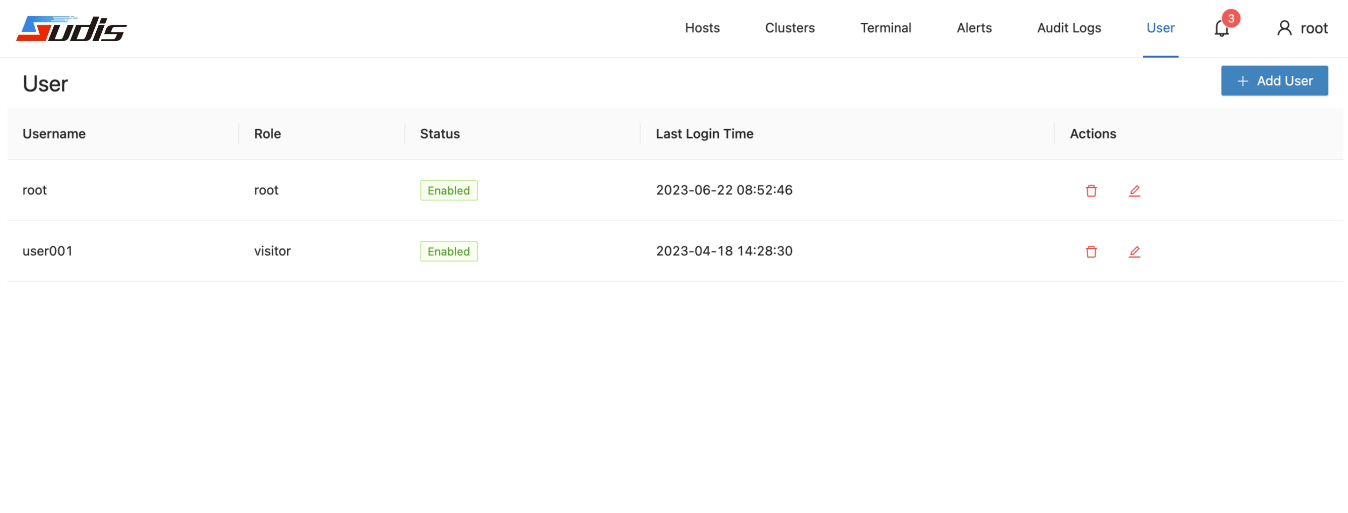
下图为Sudis告警管理界面示例:
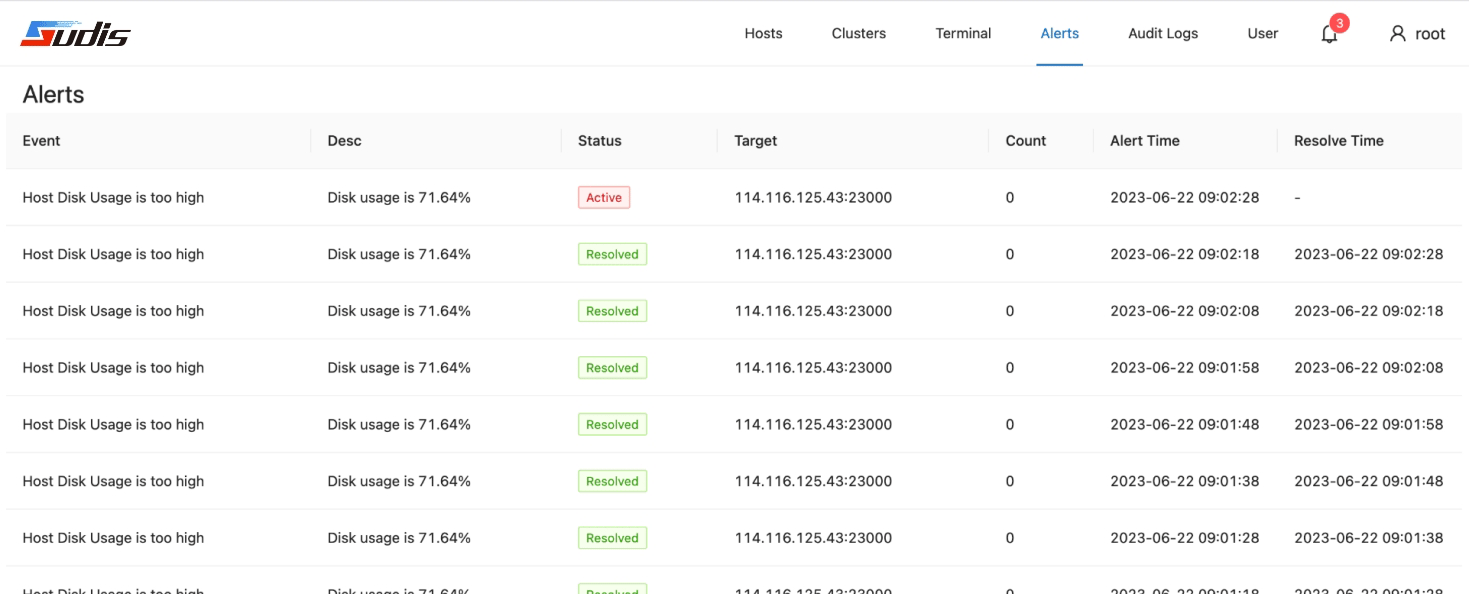
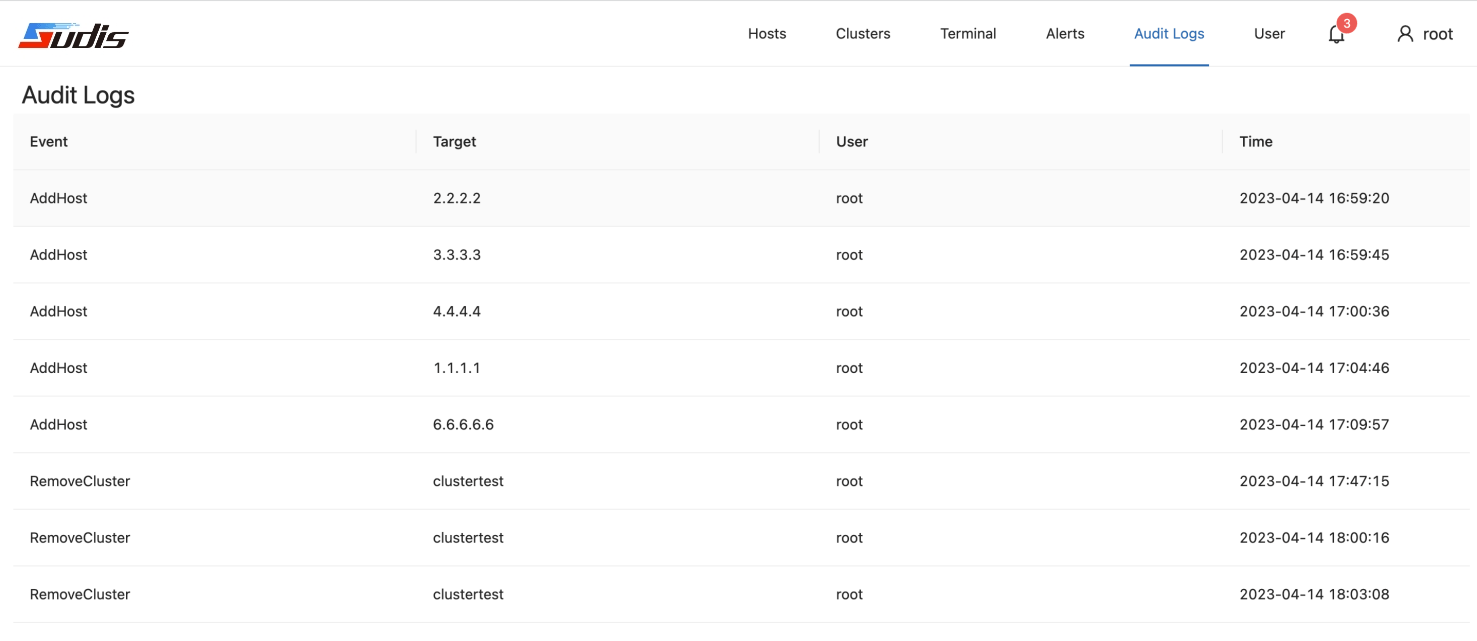
下图为Sudis审计日志管理界面示例:
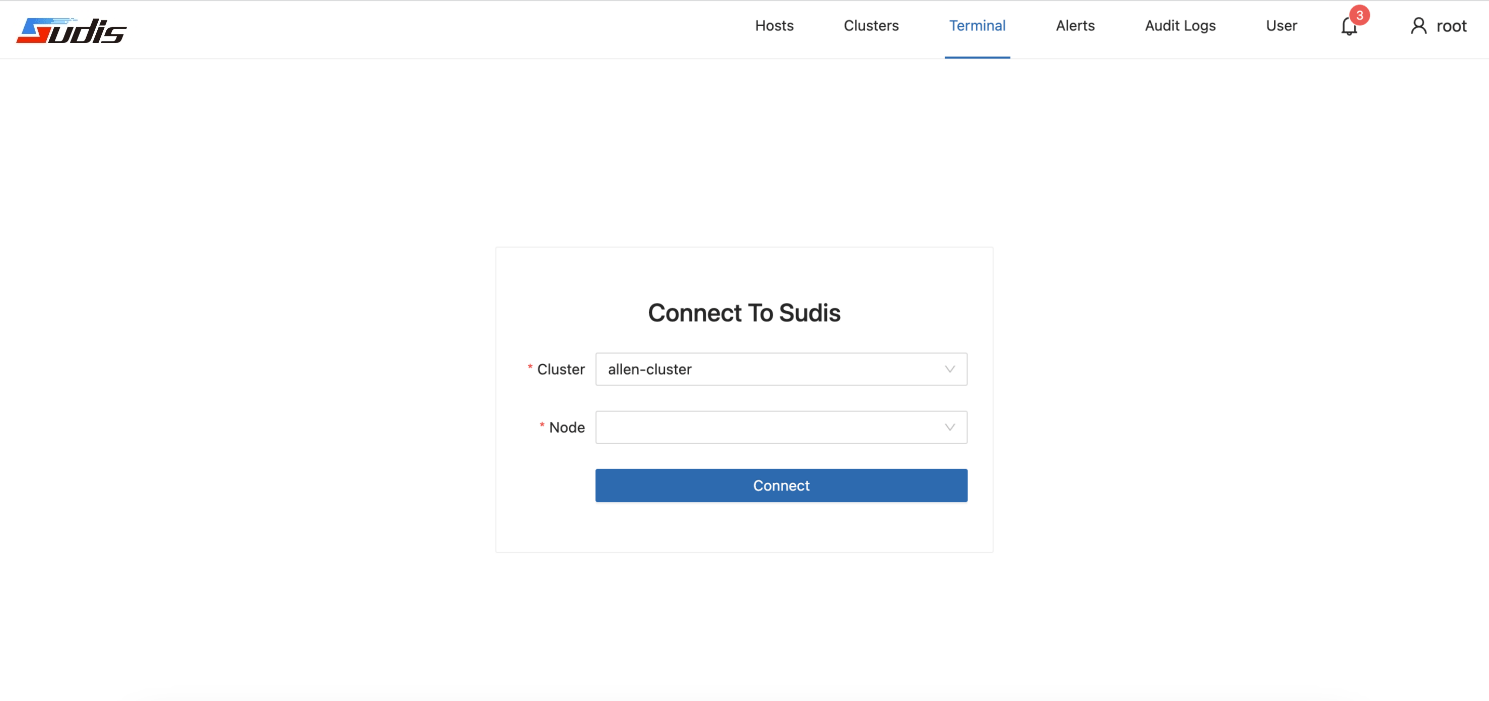
下图为Sudis web-cli界面示例:
# 产品系列
# 单机版
Sudis标准版指数据未分片的版本,是最通用的 Sudis 版本,兼容 Redis5和之前版本的协议和命令,提供数据持久化和备份,适用于对数据可靠性有要求的场景。单机版没有主从机制,不提供HA高可用,对服务高可用有要求的,建议使用集群版。
# 集群版
Sudis 集群版是采用分布式架构,支持垂直和水平的扩缩容,拥有高度的灵活性、可用性和高达千万级 QPS 的高性能。Sudis 集群版典型配置是水平方向 3 分片的扩展,每个分片作为主节点挂接两个从节点。垂直方向可实现扩展,扩容、缩容、迁移过程业务几乎无感知,做到最大的系统可用性。