# 集群简介
# Sudis集群特点
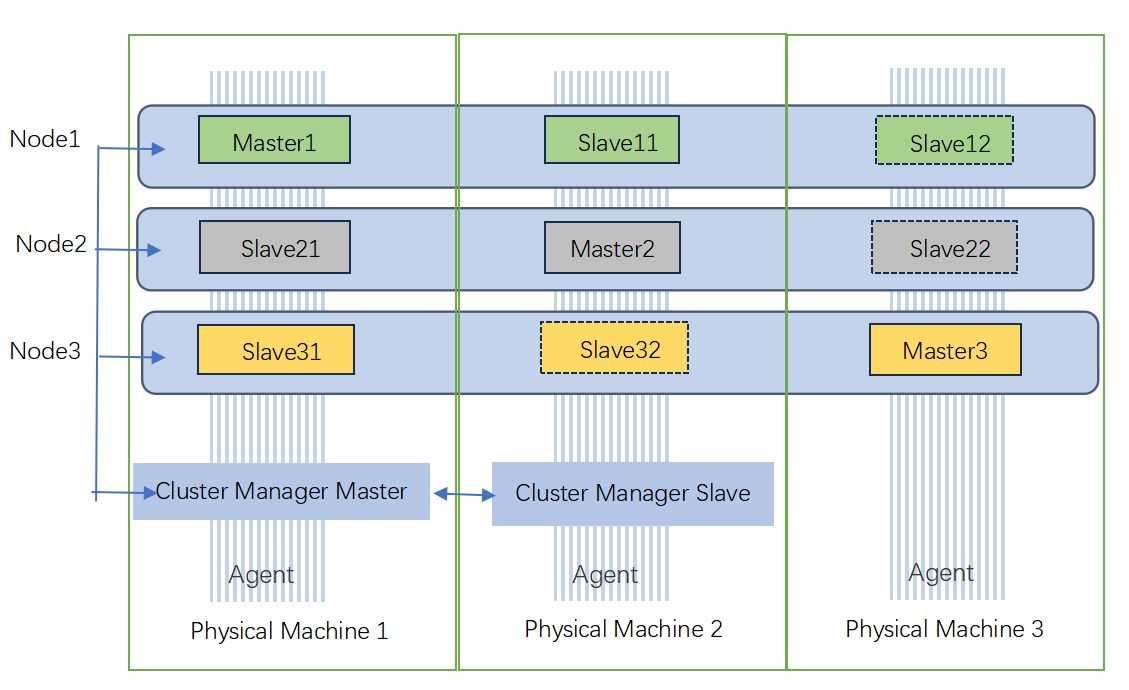
- 由Cluster Manager(Master/Slave) 负责创建管理集群,Cluster Manger Master管理事务由Cluster Manger Slave备份, 通过Agent服务进行集群的管理。
- Cluster Manager Master和Cluster Manager Slave可部署在不同的物理机上,以确保高可用,故障恢复。
- Agent service在物理机上一直启动,负责创建管理节点,创建cluster时负责拉起管理服务等,它一直处于活动状态,随时处理命令。
- 所有的集群Node至少是一主一从(也可以是一主多从),客户端可以连接任何一个主节点进行读写,从节点不提供写服务,仅作为数据备用。
- 数据按每个key的值HASH均衡分布在每个主节点Master上,每个主节点数据都存储部分数据值(如果只有一个Master主节点,则该节点存储所有数据值)
- 不支持同时处理多个key(如MSET/MGET),因为Sudis需要把key均匀分布在各个节点上,并发量很高的情况下同时创建key-value会降低性能并导致不可预测的行为。
- 支持在线增加、删除节点。
# 集群架构示意图
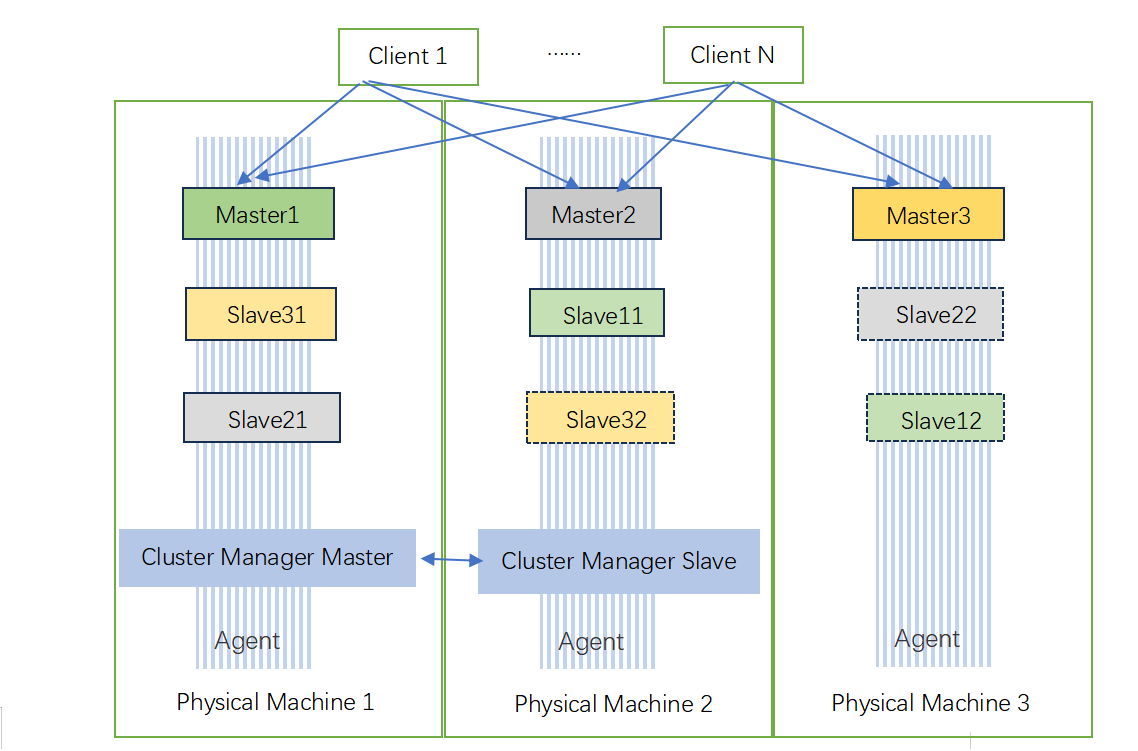
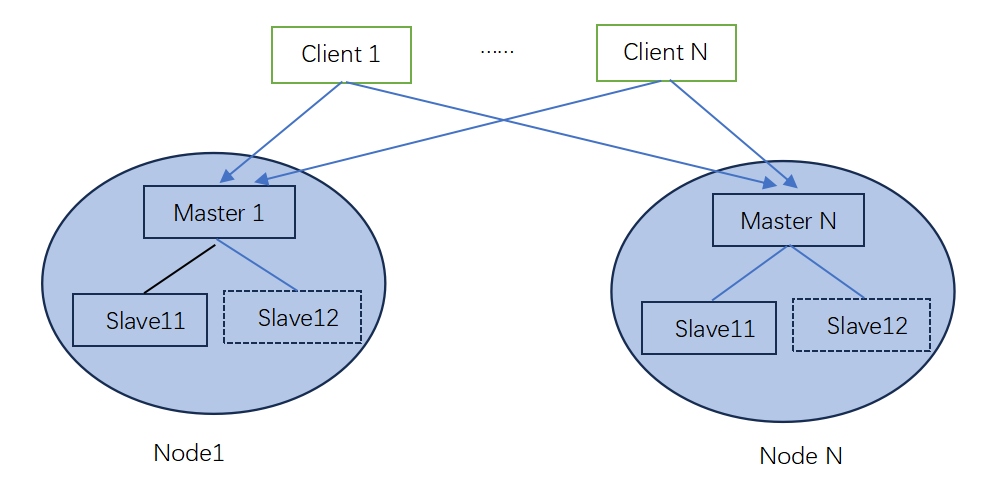
SUDIS集群最少有两个节点,即一主一从,即主备复制模式,有如下特点:
- Master数据库可以进行读写操作,当读写操作导致数据变化时会自动将数据同步给Slave数据库。
- Slave数据库一般是只读的,并且只接收Master数据库同步过来的数据。
- 一个master可以拥有多个slave,但是一个slave只能对应一个master。
- slave出现故障宕机不影响其他slave的读和master的读和写,slave重新启动后会将数据从master同步过来。
- master出现故障宕机以后,slave就会自动变成master.
- 各主节点master之间没有数据交换,只有master和slaver数据同步。
# 与开源Redis对比优势
| Sudis | 开源Redis | |
|---|---|---|
| 产品架构 | ||
| 业务场景 | ||
| 安全 | 高 | 低 |
| 数据可靠性 | ||
| 数据一致性 | 强一致性 | 弱一致性 |
# 基本原理
当新建立一个集群时,先启动 Sudis Agent服务,从服务器将向主服务器发送SYNC命令,接收到SYNC命令后的主服务器会从内存中把存量和增量数据都发送给从服务器。此后每次主服务数据发生变动都会同步给从服务器。一个主服务器可以拥有多个从服务器,而从服务器不能有从服务器,从而形成树状结构,复制功能不会阻塞主服务器,即使有一个或多个同步请求,主服务器依然能处理命令请求。
# 持久化开关
当配置了主从复制模式时需要开启主服务器的持久化功能,如果将主服务器的持久化功能关闭,主服务器一旦重启,所有从服务器的数据将会丢失。
# Slot(哈希槽)
一个Sudis集群包含16384 个插槽(hash slot),数据库中的每个键都属于这16384个插槽中的一个。插槽用来把值平均分配到不同主服务器中,达到分担压力的效果。(比如在set k1 v1操作的时候,会计算K1所在hash slot值,根据各节管理的slot值范围,放到相应的节点中去)。
集群使用公式 CRC16(key)%16384来计算键属于哪个slot。